publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- IDEAS
 29th International Symposium, IDEAS 2025, Newcastle upon Tyne, UK, July 14–16, 2025, ProceedingsGiacomo Bergami, Paul Ezhilchelvan, Yannis Manolopoulos, and 4 more authorsLecture Notes in Computer Science (Springer), 2026
29th International Symposium, IDEAS 2025, Newcastle upon Tyne, UK, July 14–16, 2025, ProceedingsGiacomo Bergami, Paul Ezhilchelvan, Yannis Manolopoulos, and 4 more authorsLecture Notes in Computer Science (Springer), 2026@article{DBLP:conf/ideas/2025, author = {Bergami, Giacomo and Ezhilchelvan, Paul and Manolopoulos, Yannis and Ilarri, Sergio and Bernardino, Jorge and Leung, Carson K. and Revesz, Peter Z.}, title = {29th International Symposium, {IDEAS} 2025, Newcastle upon Tyne, UK, July 14–16, 2025, Proceedings}, journal = {Lecture Notes in Computer Science (Springer)}, number = {15928}, publisher = {Springer}, year = {2026}, dimensions = {true}, } -
 Extracting Specifications Through Verified and Explainable AI: Interpretability, Interoperability, and Trade-OffsGiacomo Bergami, Oliver Robert Fox, and Graham Morgan2026
Extracting Specifications Through Verified and Explainable AI: Interpretability, Interoperability, and Trade-OffsGiacomo Bergami, Oliver Robert Fox, and Graham Morgan2026This chapter introduces new Verified and Explainable AI terminology to better describe such algorithms by pigeonholing them. The combined provision of three types of explainability (a priori, ad hoc, and ex post) as advocated by hybrid explainability helps with verification while improving efficiency results by better structuring the specification space and accuracy ones, by enabling both machine and human explainability of the data while providing structured and more machine-readable representation. These can then be contextualised in a general framework named General Explainable and Verifiable Artificial Intelligence (GEVAI) showcasing the possibility of combining already-existing algorithms in a full data-driven pipeline. This observation is backed up by the latest results on hybrid explainability, which outperform the current state-of-the-art results. Last, we pose some final challenges for extending GEVAI into a data science pipeline while drawing similarities with evolutionary data-aware microservice orchestration.
@inbook{chapter2025xai, author = {Bergami, Giacomo and Fox, Oliver Robert and Morgan, Graham}, editor = {Bizon, Nicu and Appasani, Bhargav}, title = {Extracting Specifications Through Verified and Explainable AI: Interpretability, Interoperability, and Trade-Offs}, booktitle = {Explainable Artificial Intelligence for Trustworthy Decisions in Smart Applications}, year = {2026}, publisher = {Springer Nature Switzerland}, address = {Cham}, pages = {33--64}, isbn = {978-3-031-97007-8}, doi = {10.1007/978-3-031-97007-8_2}, dimensions = {true}, } -
 Towards Explainable Sequential LearningGiacomo Bergami, Emma Packer, Kirsty Scott, and 1 more authorComputer Science and Information Systems, 2026
Towards Explainable Sequential LearningGiacomo Bergami, Emma Packer, Kirsty Scott, and 1 more authorComputer Science and Information Systems, 2026This paper offers a hybridly explainable temporal data processing pipeline, DataFul Explainable MultivariatE coRrelatIonal Temporal Artificial inTElligence (EMeriTAte+DF), bridging numerical-driven temporal data classification with an event-based one through verified artificial intelligence principles, enabling human explainable results. This was possible through a preliminary a posteriori explainable phase describing the numerical input data in terms of concurrent constituents with numerical payloads. This further required extending the event-based literature to design specification mining algorithms supporting concurrent constituents. Our previous and current solutions outperform state-of-the-art algorithms for multivariate time series classifications over four dataset considered in the present paper, thus showcasing the effectiveness of the proposed methodology premiering the extraction of explainable correlations across Multivariate Time Series (MTS) dimensions with dataful features.
@article{DBLP:journals/corr/abs-2505-23624, author = {Bergami, Giacomo and Packer, Emma and Scott, Kirsty and Din, Silvia Del}, title = {Towards Explainable Sequential Learning}, journal = {Computer Science and Information Systems}, volume = {23}, year = {2026}, number = {1}, doi = {https://doi.org/10.2298/CSIS250303077B}, eprinttype = {arXiv}, dimensions = {true}, issn = {2406-1018}, pages = {443-473} }
2025
-
 Federated Load Balancing in Smart Cities: A 6G, Cloud, and Agentic AI PerspectiveRohin Gillgallon, Giacomo Bergami, and Graham MorganApplied Sciences, 2025
Federated Load Balancing in Smart Cities: A 6G, Cloud, and Agentic AI PerspectiveRohin Gillgallon, Giacomo Bergami, and Graham MorganApplied Sciences, 2025Modern smart cities are comprised of multiple sensors, all with their own collection of communicating devices transmitting data towards cloud data centres for analysis. Smart cities have limited bandwidth resources, which, if not managed correctly, can lead to network bottlenecks. These bottlenecks are commonly addressed through bottleneck mitigation strategies and load balancing algorithms, which aim to maximise the throughput of a smart city’s network infrastructure. Network simulators are a crucial tool for developing and testing bottleneck mitigation and load balancing techniques before deployment in real systems; however, many network simulators are developed as single-purpose tools, aiming to simulate a particular subset of an overarching use case. Such tools are therefore unable to model a real-world smart city infrastructure, which receives communications across a wide range of scenarios and from a wide variety of devices. This paper surveys the current state-of-the-art for network simulation tools, modern bottleneck mitigation strategies and load balancing techniques, evaluating each in terms of its suitability for smart cities and smart city simulation. This survey finds there is a lack of current network simulation tools up to the task of modelling smart city infrastructure and found no such simulation tools capable of modelling both smart city infrastructure and implementing the state-of-the-art bottleneck mitigation and load balancing strategies outlined within this work, highlighting this as a significant gap in current research before providing future work suggestions, including a federated approach for future simulation tools.
@article{metasimulator, author = {Gillgallon, Rohin and Bergami, Giacomo and Morgan, Graham}, title = {Federated Load Balancing in Smart Cities: A 6G, Cloud, and Agentic AI Perspective}, journal = {Applied Sciences}, volume = {15}, year = {2025}, number = {20}, article-number = {10920}, issn = {2076-3417}, doi = {10.3390/app152010920}, dimensions = {true}, } -
 Verified Language Processing with Hybrid ExplainabilityOliver Robert Fox, Giacomo Bergami, and Graham MorganElectronics, 2025
Verified Language Processing with Hybrid ExplainabilityOliver Robert Fox, Giacomo Bergami, and Graham MorganElectronics, 2025The volume and diversity of digital information have led to a growing reliance on Machine Learning (ML) techniques, such as Natural Language Processing (NLP), for interpreting and accessing appropriate data. While vector and graph embeddings represent data for similarity tasks, current state-of-the-art pipelines lack guaranteed explainability, failing to accurately determine similarity for given full texts. These considerations can also be applied to classifiers exploiting generative language models with logical prompts, which fail to correctly distinguish between logical implication, indifference, and inconsistency, despite being explicitly trained to recognise the first two classes. We present a novel pipeline designed for hybrid explainability to address this. Our methodology combines graphs and logic to produce First-Order Logic (FOL) representations, creating machine- and human-readable representations through Montague Grammar (MG). The preliminary results indicate the effectiveness of this approach in accurately capturing full text similarity. To the best of our knowledge, this is the first approach to differentiate between implication, inconsistency, and indifference for text classification tasks. To address the limitations of existing approaches, we use three self-contained datasets annotated for the former classification task to determine the suitability of these approaches in capturing sentence structure equivalence, logical connectives, and spatiotemporal reasoning. We also use these data to compare the proposed method with language models pre-trained for detecting sentence entailment. The results show that the proposed method outperforms state-of-the-art models, indicating that natural language understanding cannot be easily generalised by training over extensive document corpora. This work offers a step toward more transparent and reliable Information Retrieval (IR) from extensive textual data.
@article{electronics14173490, author = {Fox, Oliver Robert and Bergami, Giacomo and Morgan, Graham}, title = {Verified Language Processing with Hybrid Explainability}, journal = {Electronics}, dimensions = {true}, volume = {14}, year = {2025}, number = {17}, article-number = {3490}, url = {https://www.mdpi.com/2079-9292/14/17/3490}, issn = {2079-9292}, doi = {10.3390/electronics14173490} } -
 How Explainable Really is AI? Benchmarking Explainable AIGiacomo Bergami, and Oliver Robert FoxLogics, 2025
How Explainable Really is AI? Benchmarking Explainable AIGiacomo Bergami, and Oliver Robert FoxLogics, 2025This work contextualizes the possibility of deriving a unifying artificial intelligence framework by walking in the footsteps of General, Explainable, and Verified Artificial Intelligence (GEVAI): by considering explainability not only at the level of the results produced by a specification but also considering the explicability of the inference process as well as the one related to the data processing step, we can not only ensure human explainability of the process leading to the ultimate results but also mitigate and minimize machine faults leading to incorrect results. This, on the other hand, requires the adoption of automated verification processes beyond system fine-tuning, which are essentially relevant in a more interconnected world. The challenges related to full automation of a data processing pipeline, mostly requiring human-in-the-loop approaches, forces us to tackle the framework from a different perspective: while proposing a preliminary implementation of GEVAI mainly used as an AI test-bed having different state-of-the-art AI algorithms interconnected, we propose two other data processing pipelines, LaSSI and EMeriTAte+DF, being a specific instantiation of GEVAI for solving specific problems (Natural Language Processing, and Multivariate Time Series Classifications). Preliminary results from our ongoing work strengthen the position of the proposed framework by showcasing it as a viable path to improve current state-of-the-art AI algorithms.
@article{logics2020005, author = {Bergami, Giacomo and Fox, Oliver Robert}, title = {How Explainable Really is AI? Benchmarking Explainable AI }, journal = {Logics}, volume = {3}, year = {2025}, number = {3}, article-number = {9}, issn = {2813-0405}, doi = {10.3390/logics3030009}, dimensions = {true}, } - From Camera Image to Active Target Tracking: Modelling, Encoding and Metrical Analysis for Unmanned Underwater VehiclesSamuel Appleby, Giacomo Bergami, and Gary UshawAI, 2025
Marine mammal monitoring, a growing field of research, is critical to cetacean conservation. Traditional ‘tagging’ attaches sensors such as GPS to such animals, though these are intrusive and susceptible to infection and, ultimately, death. A less intrusive approach exploits UUV commanded by a human operator above ground. The development of AI for autonomous underwater vehicle navigation models training environments in simulation, providing visual and physical fidelity suitable for sim-to-real transfer. Previous solutions, including UVMS and L2D, provide only satisfactory results, due to poor environment generalisation while sensors including sonar create environmental disturbances. Though rich in features, image data suffer from high dimensionality, providing a state space too great for many machine learning tasks. Underwater environments, susceptible to image noise, further complicate this issue. We propose SWIM v2.0,type=symbolslist,unit=
@article{ai6040071, author = {Appleby, Samuel and Bergami, Giacomo and Ushaw, Gary}, title = {From Camera Image to Active Target Tracking: Modelling, Encoding and Metrical Analysis for Unmanned Underwater Vehicles}, journal = {AI}, volume = {6}, year = {2025}, number = {4}, article-number = {71}, url = {https://www.mdpi.com/2673-2688/6/4/71}, issn = {2673-2688}, doi = {10.3390/ai6040071}, dimensions = {true}, } - SimulatorOrchestrator: A 6G-Ready Simulator for the Cell-Free/Osmotic InfrastructureSensors, 2025
To the best of our knowledge, we offer the first IoT-Osmotic simulator supporting 6G and Cloud infrastructures, leveraging the similarities in Software-Defined Wide Area Network (SD-WAN) architectures when used in Osmotic architectures and User-Centric Cell-Free mMIMO (massive multiple-input multiple-output) architectures. Our simulator acts as a simulator orchestrator, supporting the interaction with a patient digital twin generating patient healthcare data (vital signs and emergency alerts) and a VANET simulator (SUMO), both leading to IoT data streams towards the cloud through pre-initiated MQTT protocols. This contextualises our approach within the healthcare domain while showcasing the possibility of orchestrating different simulators at the same time. The combined provision of these two aspects, joined with the addition of a ring network connecting all the first-mile edge nodes (i.e., access points), enables the definition of new packet routing algorithms, streamlining previous solutions from SD-WAN architectures, thus showing the benefit of 6G architectures in achieving better network load balancing, as well as showcasing the limitations of previous approaches. The simulated 6G architecture, combined with the optimal routing algorithm and MEL (Microelements software components) allocation policy, was able to reduce the time required to route all communications from IoT devices to the cloud by up to 50.4% compared to analogous routing algorithms used within 5G architectures.
@article{s25051591, author = {Gillgallon, Rohin and Almutairi, Reham and Bergami, Giacomo and Morgan, Graham}, title = {SimulatorOrchestrator: A 6G-Ready Simulator for the Cell-Free/Osmotic Infrastructure}, journal = {Sensors}, volume = {25}, year = {2025}, number = {5}, article-number = {1591}, url = {https://www.mdpi.com/1424-8220/25/5/1591}, issn = {1424-8220}, publisher = {MDPI}, dimensions = {true}, doi = {10.3390/s25051591}, c = {https://www.preprints.org/manuscript/202502.0523/v1} } - AI-Driven Multi-Agent Vehicular Planning for Battery Efficiency and QoS in 6G Smart CitiesIn 16th International Conference, MEDES 2025, Ho Chi Minh, Vietnam, November 24–26, 2025, Proceedings, 2025
@inproceedings{potmoast, title = {AI-Driven Multi-Agent Vehicular Planning for Battery Efficiency and QoS in 6G Smart Cities}, author = {Gillgallon, Rohin and Bergami, Giacomo and Almutairi, Reham and Morgan, Graham}, year = {2025}, booktitle = {16th International Conference, MEDES 2025, Ho Chi Minh, Vietnam, November 24–26, 2025, Proceedings}, series = {Communications in Computer and Information Science}, publisher = {Springer}, dimensions = {true}, } - SimulatorBridgerDfT: A Real-Data Simulator for IoT-Osmotic InteractionsReham Almutairi, Giacomo Bergami, and Graham MorganIn Proceedings of the 2024 the 12th International Conference on Information Technology (ICIT), , 2025
Urban traffic simulation is crucial for improving traffic management by analyzing and optimizing urban mobility. Traditional VANET simulation tools, using traffic data from simulators like SUMO, lack real-world data integration. SimulatorBridgerDfT addresses this by extending SimulatorBridger to incorporate real-world traffic data from the UK’s Department for Transport (DfT). It processes diverse data formats, particularly CSV from the DfT, for more accurate urban traffic simulations. The research examines how real-world traffic data affects vehicular network communication times. Experiments show that SimulatorBridgerDfT accurately mirrors real-world traffic and reveals the impact of increased IoT device loads on network performance, emphasizing the need for effective smart city network management.
2024
-
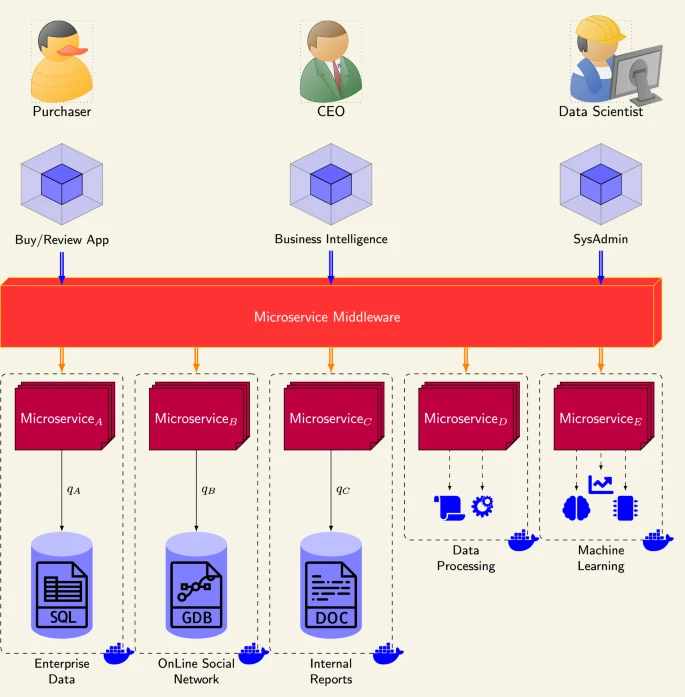 Towards automating microservices orchestration through data-driven evolutionary architecturesGiacomo BergamiService Oriented Computing and Applications, Mar 2024
Towards automating microservices orchestration through data-driven evolutionary architecturesGiacomo BergamiService Oriented Computing and Applications, Mar 2024This paper briefly outlines current literature on evolutionary architectures and current links with microservices orchestration and data integration. We also propose future research directions bridging the field of service-oriented architectures with the data science domain.
@article{bergami2024, author = {Bergami, Giacomo}, title = {Towards automating microservices orchestration through data-driven evolutionary architectures}, journal = {Service Oriented Computing and Applications}, year = {2024}, month = mar, day = {01}, volume = {18}, number = {1}, pages = {1-12}, issn = {1863-2394}, doi = {10.1007/s11761-024-00387-x}, url = {https://doi.org/10.1007/s11761-024-00387-x}, publisher = {MDPI}, dimensions = {true}, } - DECLAREd: A Polytime LTLf FragmentGiacomo BergamiLogics, Mar 2024
This paper considers a specification rewriting meachanism for a specific fragment of Linear Temporal Logic for Finite traces, DECLAREd, working through an equational logic and rewriting mechanism under customary practitioner assumptions from the Business Process Management literature. By rewriting the specification into an equivalent formula which might be easier to compute, we aim to streamline current state-of-the-art temporal artificial intelligence algorithms working on temporal logic. As this specification rewriting mechanism is ultimately also able to determine with the provided specification is a tautology (always true formula) or a formula containing a temporal contradiction, by detecting the necessity of a specific activity label to be both present and absent within a log, this implies that the proved mechanism is ultimately a SAT-solver for DECLAREd. We prove for the first time, to the best of our knowledge, that this fragment is a polytime fragment of LTLf, while all the previously-investigated fragments or extensions of such a language were in polyspace. We test these considerations over formal synthesis (Lydia), SAT-Solvers (AALTAF) and formal verification (KnoBAB) algorithms, where formal verification can be also run on top of a relational database and can be therefore expressed in terms of relational query answering. We show that all these benefit from the aforementioned assumptions, as running their tasks over a rewritten equivalent specification will improve their running times, thus motivating the pressing need of this approach for practical temporal artificial intelligence scenarios. We validate such claims by testing such algorithms over a Cybersecurity dataset.
@article{logics2020004, author = {Bergami, Giacomo}, title = {DECLAREd: A Polytime LTLf Fragment}, journal = {Logics}, volume = {2}, year = {2024}, number = {2}, pages = {79--111}, url = {https://www.mdpi.com/2813-0405/2/2/4}, issm = {2813-0405}, doi = {10.3390/logics2020004}, dimensions = {true}, } - Best Paper Award Predicting Dyskinetic Events Through Verified Multivariate Time Series ClassificationGiacomo Bergami, Emma Packer, Kirsty Scott, and 1 more authorIn Database Engineered Applications - 28th International Symposium, IDEAS 2024, Bayonne, France, August 26-29, 2024, Proceedings, Mar 2024
@inproceedings{ideas2024a, author = {Bergami, Giacomo and Packer, Emma and Scott, Kirsty and Din, Silvia Del}, editor = {Chbeir, Richard and Ilarri, Sergio and Manolopoulos, Yannis and Revesz, Peter Z. and Bernardino, Jorge and Leung, Carson K.}, title = {Predicting Dyskinetic Events Through Verified Multivariate Time Series Classification}, booktitle = {Database Engineered Applications - 28th International Symposium, {IDEAS} 2024, Bayonne, France, August 26-29, 2024, Proceedings}, series = {Lecture Notes in Computer Science}, volume = {15511}, pages = {49--62}, publisher = {Springer}, year = {2024}, url = {https://doi.org/10.1007/978-3-031-83472-1\_4}, doi = {10.1007/978-3-031-83472-1\_4}, timestamp = {Wed, 02 Apr 2025 17:00:22 +0200}, biburl = {https://dblp.org/rec/conf/ideas/BergamiPSD24.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, dimensions = {true}, } - IDEAS LaSSI: Logical, Structural, and Semantic Text InterpretationOliver Robert Fox, Giacomo Bergami, and Graham MorganIn Database Engineered Applications - 28th International Symposium, IDEAS 2024, Bayonne, France, August 26-29, 2024, Proceedings, Mar 2024
@inproceedings{ideas2024b, author = {Fox, Oliver Robert and Bergami, Giacomo and Morgan, Graham}, editor = {Chbeir, Richard and Ilarri, Sergio and Manolopoulos, Yannis and Revesz, Peter Z. and Bernardino, Jorge and Leung, Carson K.}, title = {LaSSI: Logical, Structural, and Semantic Text Interpretation}, booktitle = {Database Engineered Applications - 28th International Symposium, {IDEAS} 2024, Bayonne, France, August 26-29, 2024, Proceedings}, series = {Lecture Notes in Computer Science}, volume = {15511}, pages = {106--121}, publisher = {Springer}, year = {2024}, url = {https://doi.org/10.1007/978-3-031-83472-1\_8}, doi = {10.1007/978-3-031-83472-1\_8}, timestamp = {Wed, 02 Apr 2025 17:00:22 +0200}, biburl = {https://dblp.org/rec/conf/ideas/FoxBM24.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, dimensions = {true}, } - Best Paper Award Approximating Real-Time IoT Interaction Through Connection Counting: A QoS PerspectiveIn 2024 20th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Mar 2024
@inproceedings{simbridger2, author = {Almutairi, Reham and Gillgallon, Rohin and Bergami, Giacomo and Morgan, Graham}, booktitle = {2024 20th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob)}, title = {Approximating Real-Time IoT Interaction Through Connection Counting: A QoS Perspective}, year = {2024}, volume = {}, number = {}, pages = {260-265}, keywords = {Wireless communication;Performance evaluation;Patient monitoring;Quality of service;Real-time systems;Internet of Things;Resource management;Reliability;Optimization;Mobile computing;IoT;Healthcare Transportation;Traffic Simulators;Patient Monitoring}, doi = {10.1109/WiMob61911.2024.10770322}, dimensions = {true}, } - Systematic Literature Review of VANET Simulators: Comparative Analysis, Technological Advancements, and Research ChallengesReham Almutairi, Giacomo Bergami, and Graham MorganIn 2024 International Symposium on Parallel Computing and Distributed Systems (PCDS), Mar 2024
@inproceedings{nabro, author = {Almutairi, Reham and Bergami, Giacomo and Morgan, Graham}, booktitle = {2024 International Symposium on Parallel Computing and Distributed Systems (PCDS)}, title = {Systematic Literature Review of VANET Simulators: Comparative Analysis, Technological Advancements, and Research Challenges}, year = {2024}, volume = {}, number = {}, pages = {1-11}, keywords = {Renewable energy sources;5G mobile communication;Vehicular ad hoc networks;Transportation;Battery management systems;Real-time systems;Encryption;Batteries;Testing;Edge computing;VANET Simulators;Traffic Simulator;VANET}, doi = {10.1109/PCDS61776.2024.10743218}, dimensions = {true}, } - Testing Routing Strategies by Simulating the Mobile IoT Edge/Cloud ContinuumRohin Gillgallon, Giacomo Bergami, and Graham MorganIn 2024 IEEE International Smart Cities Conference (ISC2), Mar 2024
@inproceedings{ISC224, author = {Gillgallon, Rohin and Bergami, Giacomo and Morgan, Graham}, booktitle = {2024 IEEE International Smart Cities Conference (ISC2)}, title = {Testing Routing Strategies by Simulating the Mobile IoT Edge/Cloud Continuum}, year = {2024}, volume = {}, number = {}, pages = {1-6}, keywords = {Cellular networks;Limiting;Smart cities;Software algorithms;Routing;Scheduling;Delays;Internet of Things;Software defined networking;Testing;Cellular Networks;Cloud Simulator;Software Defined Networks}, doi = {10.1109/ISC260477.2024.11004296}, dimensions = {true}, } - Poster: IoTSimSecure: Towards an IoT Simulator Supporting Cyber-Threat Detection AlgorithmsReham Almutairi, Giacomo Bergami, and Graham MorganIn 8th IEEE International Conference on Fog and Edge Computing, May 2024
@inproceedings{security, author = {Almutairi, Reham and Bergami, Giacomo and Morgan, Graham}, booktitle = {8th {IEEE} International Conference on Fog and Edge Computing}, title = {Poster: IoTSimSecure: Towards an IoT Simulator Supporting Cyber-Threat Detection Algorithms}, year = {2024}, volume = {}, number = {}, series = {ICFEC (in press)}, month = may, dimensions = {true}, } -
 Matching and Rewriting Rules in Object-Oriented DatabasesGiacomo Bergami, Oliver Robert Fox, and Graham MorganMathematics, May 2024
Matching and Rewriting Rules in Object-Oriented DatabasesGiacomo Bergami, Oliver Robert Fox, and Graham MorganMathematics, May 2024Graph query languages such as Cypher are widely adopted to match and retrieve data in a graph representation, due to their ability to retrieve and transform information. Even though the most natural way to match and transform information is through rewriting rules, those are scarcely or partially adopted in graph query languages. Their inability to do so has a major impact on the subsequent way the information is structured, as it might then appear more natural to provide major constraints over the data representation to fix the way the information should be represented. On the other hand, recent works are starting to move towards the opposite direction, as the provision of a truly general semistructured model (GSM) allows to both represent all the available data formats (Network-Based, Relational, and Semistructured) as well as support a holistic query language expressing all major queries in such languages. In this paper, we show that the usage of GSM enables the definition of a general rewriting mechanism which can be expressed in current graph query languages only at the cost of adhering the query to the specificity of the underlying data representation. We formalise the proposed query language in terms declarative graph rewriting mechanisms described as a set of production rules L→R while both providing restriction to the characterisation of L, and extending it to support structural graph nesting operations, useful to aggregate similar information around an entry-point of interest. We further achieve our declarative requirements by determining the order in which the data should be rewritten and multiple rules should be applied while ensuring the application of such updates on the GSM database is persisted in subsequent rewriting calls. We discuss how GSM, by fully supporting index-based data representation, allows for a better physical model implementation leveraging the benefits of columnar database storage. Preliminary benchmarks show the scalability of this proposed implementation in comparison with state-of-the-art implementations.
@article{math12172677, author = {Bergami, Giacomo and Fox, Oliver Robert and Morgan, Graham}, title = {Matching and Rewriting Rules in Object-Oriented Databases}, journal = {Mathematics}, volume = {12}, year = {2024}, issue = {17}, number = {2677}, url = {https://www.mdpi.com/2227-7390/12/17/2677}, issn = {2227-7390}, doi = {10.3390/math12172677}, dimensions = {true}, } - Generalised Graph Grammars for Natural Language ProcessingOliver Robert Fox, and Giacomo BergamiMay 2024
In the graph database literature the term "join" does not refer to an operator used to merge two graphs. In particular, a counterpart of the relational join is not present in existing graph query languages, and consequently no efficient algorithms have been developed for this operator. This paper provides two main contributions. First, we define a binary graph join operator that acts on the vertices as a standard relational join and combines the edges according to a user-defined semantics. Then we propose the "CoGrouped Graph Conjunctive θ-Join" algorithm running over data indexed in secondary memory. Our implementation outperforms the execution of the same operation in Cypher and SPARQL on major existing graph database management systems by at least one order of magnitude, also including indexing and loading time.
@misc{fox2024generalisedgraphgrammarsnatural, title = {Generalised Graph Grammars for Natural Language Processing}, author = {Fox, Oliver Robert and Bergami, Giacomo}, year = {2024}, eprint = {2403.07481}, archiveprefix = {arXiv}, primaryclass = {cs.DB}, url = {https://arxiv.org/abs/2403.07481}, dimensions = {true}, } - Inf. Streamlining Temporal Formal Verification over Columnar DatabasesGiacomo BergamiInformation, May 2024
Recent findings demonstrate how database technology enhances the computation of formal verification tasks expressible in linear time logic for finite traces (LTLf). Human-readable declarative languages also help the common practitioner to express temporal constraints in a straightforward and accessible language. Notwithstanding the former, this technology is in its infancy, and therefore, few optimization algorithms are known for dealing with massive amounts of information audited from real systems. We, therefore, present four novel algorithms subsuming entire LTLf expressions while outperforming previous state-of-the-art implementations on top of KnoBAB, thus postulating the need for the corresponding, leading to the formulation of novel xtLTLf-derived algebraic operators.
@article{info15010034, author = {Bergami, Giacomo}, title = {Streamlining Temporal Formal Verification over Columnar Databases}, journal = {Information}, volume = {15}, year = {2024}, issue = {1}, number = {34}, url = {https://www.mdpi.com/2078-2489/15/1/34}, issn = {2078-2489}, doi = {10.3390/info15010034}, dimensions = {true}, } - Advancements and Challenges in IoT Simulators: A Comprehensive ReviewReham Almutairi, Giacomo Bergami, and Graham MorganSensors, May 2024
The Internet of Things (IoT) has emerged as an important concept, bridging the physical and digital worlds through interconnected devices. Although the idea of interconnected devices predates the term “Internet of Things”, which was coined in 1999 by Kevin Ashton, the vision of a seamlessly integrated world of devices has been accelerated by advancements in wireless technologies, cost-effective computing, and the ubiquity of mobile devices. This study aims to provide an in-depth review of existing and emerging IoT simulators focusing on their capabilities and real-world applications, and discuss the current challenges and future trends in the IoT simulation area. Despite substantial research in the IoT simulation domain, many studies have a narrow focus, leaving a gap in comprehensive reviews that consider broader IoT development metrics, such as device mobility, energy models, Software-Defined Networking (SDN), and scalability. Notably, there is a lack of literature examining IoT simulators’ capabilities in supporting renewable energy sources and their integration with Vehicular Ad-hoc Network (VANET) simulations. Our review seeks to address this gap, evaluating the ability of IoT simulators to simulate complex, large-scale IoT scenarios and meet specific developmental requirements, as well as examining the current challenges and future trends in the field of IoT simulation. Our systematic analysis has identified several significant gaps in the current literature. A primary concern is the lack of a generic simulator capable of effectively simulating various scenarios across different domains within the IoT environment. As a result, a comprehensive and versatile simulator is required to simulate the diverse scenarios occurring in IoT applications. Additionally, there is a notable gap in simulators that address specific security concerns, particularly battery depletion attacks, which are increasingly relevant in IoT systems. Furthermore, there is a need for further investigation and study regarding the integration of IoT simulators with traffic simulation for VANET environments. In addition, it is noteworthy that renewable energy sources are underrepresented in IoT simulations, despite an increasing global emphasis on environmental sustainability. As a result of these identified gaps, it is imperative to develop more advanced and adaptable IoT simulation tools that are designed to meet the multifaceted challenges and opportunities of the IoT domain.
@article{s24051511, author = {Almutairi, Reham and Bergami, Giacomo and Morgan, Graham}, title = {Advancements and Challenges in IoT Simulators: A Comprehensive Review}, journal = {Sensors}, volume = {24}, year = {2024}, issue = {5}, number = {1511}, url = {https://www.mdpi.com/1424-8220/24/5/1511}, pubmedid = {38475047}, issn = {1424-8220}, doi = {10.3390/s24051511}, dimensions = {true}, } - SimulatorBridger: System for Monitoring Energy Efficiency of Electric Vehicles in Real-World Traffic SimulationsReham Almutairi, Giacomo Bergami, and Graham MorganJournal of Engineering Research and Sciences, May 2024
The increasing popularity and attention in Vehicular Ad-hoc Networks (VANETs) have prompted researchers to develop accurate and realistic simulation tools. Realistic simulation for VANETs is challenging due to the high mobility of vehicles and the need to integrate various communication modalities such as Vehicle-to-Infrastructure (V2I) and Vehicle-to-Vehicle (V2V) interactions. Existing simulators lack the capability to simulate VANET environments based on IoT infrastructure. In this work, we propose SimulatorBridger, a novel simulator that bridges IoTSim-OsmosisRES with SUMO, a traffic simulator, to simulate VANET environments with integrated IoT infrastructure. Our study focuses on analyzing the generated dataflows from V2I and V2V interactions and their impact on vehicle energy efficiency. Even though On-Board Units (OBUs) appear to have insignificant energy demands compared to other vehicle energy consumptions such as electric motors or auxiliary systems (HVAC, lights, comfort facilities), we found a near-perfect correlation between the intensity of communication dataflows and the battery consumption. This correlation indicates that increased communication activity can contribute to an increase in overall energy consumption. Furthermore, we propose future research directions, including traffic rerouting based on battery consumption optimization, which can be efficiently tested using our simulation platform. By including communication energy costs in the design of energy-efficient vehicular networks, these insights contribute to a deeper understanding of energy management in VANETs.
@article{almutairi2024, author = {Almutairi, Reham and Bergami, Giacomo and Morgan, Graham}, doi = {10.55708/js0306004}, issue = {6}, journal = {Journal of Engineering Research and Sciences}, keywords = {IoT,Traffic Simultors,VANET}, pages = {33-40}, title = {SimulatorBridger: System for Monitoring Energy Efficiency of Electric Vehicles in Real-World Traffic Simulations}, volume = {3}, year = {2024}, dimensions = {true}, }
2023
- Specification Mining over Temporal DataGiacomo Bergami, Samuel Appleby, and Graham MorganComputers, May 2023
Current specification mining algorithms for temporal data rely on exhaustive search approaches, which become detrimental in real data settings where a plethora of distinct temporal behaviours are recorded over prolonged observations. This paper proposes a novel algorithm, Bolt2, based on a refined heuristic search of our previous algorithm, Bolt. Our experiments show that the proposed approach not only surpasses exhaustive search methods in terms of running time but also guarantees a minimal description that captures the overall temporal behaviour. This is achieved through a hypothesis lattice search that exploits support metrics. Our novel specification mining algorithm also outperforms the results achieved in our previous contribution.
@article{computers12090185, author = {Bergami, Giacomo and Appleby, Samuel and Morgan, Graham}, title = {Specification Mining over Temporal Data}, journal = {Computers}, volume = {12}, year = {2023}, issue = {9}, number = {185}, url = {https://www.mdpi.com/2073-431X/12/9/185}, issn = {2073-431X}, doi = {10.3390/computers12090185}, dimensions = {true}, } - Inf. Quickening Data-Aware Conformance Checking through Temporal AlgebrasGiacomo Bergami, Samuel Appleby, and Graham MorganInformation, May 2023
A temporal model describes processes as a sequence of observable events characterised by distinguishable actions in time. Conformance checking allows these models to determine whether any sequence of temporally ordered and fully-observable events complies with their prescriptions. The latter aspect leads to Explainable and Trustworthy AI, as we can immediately assess the flaws in the recorded behaviours while suggesting any possible way to amend the wrongdoings. Recent findings on conformance checking and temporal learning lead to an interest in temporal models beyond the usual business process management community, thus including other domain areas such as Cyber Security, Industry 4.0, and e-Health. As current technologies for accessing this are purely formal and not ready for the real world returning large data volumes, the need to improve existing conformance checking and temporal model mining algorithms to make Explainable and Trustworthy AI more efficient and competitive is increasingly pressing. To effectively meet such demands, this paper offers KnoBAB, a novel business process management system for efficient Conformance Checking computations performed on top of a customised relational model. This architecture was implemented from scratch after following common practices in the design of relational database management systems. After defining our proposed temporal algebra for temporal queries (xtLTLf), we show that this can express existing temporal languages over finite and non-empty traces such as LTLf. This paper also proposes a parallelisation strategy for such queries, thus reducing conformance checking into an embarrassingly parallel problem leading to super-linear speed up. This paper also presents how a single xtLTLf operator (or even entire sub-expressions) might be efficiently implemented via different algorithms, thus paving the way to future algorithmic improvements. Finally, our benchmarks highlight that our proposed implementation of xtLTLf (KnoBAB) outperforms state-of-the-art conformance checking software running on LTLf logic.
@article{info14030173, author = {Bergami, Giacomo and Appleby, Samuel and Morgan, Graham}, title = {Quickening Data-Aware Conformance Checking through Temporal Algebras}, journal = {Information}, volume = {14}, year = {2023}, issue = {3}, number = {173}, url = {https://www.mdpi.com/2078-2489/14/3/173}, issn = {2078-2489}, doi = {10.3390/info14030173}, dimensions = {true}, } - Towards a Generalised Semistructured Data Model and Query LanguageGiacomo Bergami, and Wiktor ZegadłoSIGWEB Newsl., Aug 2023
Although current efforts are all aimed at re-defining new ways to harness old data representations, possibly with new schema features, the challenges still open provide evidence of the need for a "diametrically opposite" approach: in fact, all information generated in real contexts is to be understood lacking of any form of schema, where the schema associated with such data is only determined a posteriori based on either a specific application context, or from some data’s facets of interest. This solution should still enable recommendation systems to manipulate the aforementioned data semantically. After providing evidence of these limitations from current literature, we propose a new Generalized Semistructured data Model that makes possible queries expressible in any data representation through a Generalised Semistructured Query Language, both relying upon script v2.0 as a MetaModel language manipulating types as terms as well as allowing structural aggregation functions.
@article{zegadlo, author = {Bergami, Giacomo and Zegad\l{}o, Wiktor}, title = {Towards a Generalised Semistructured Data Model and Query Language}, year = {2023}, issue_date = {Summer 2023}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, volume = {2023}, number = {Summer}, issn = {1931-1745}, url = {https://doi.org/10.1145/3609429.3609433}, doi = {10.1145/3609429.3609433}, journal = {SIGWEB Newsl.}, month = aug, articleno = {4}, numpages = {22}, dimensions = {true}, } - IDEAS Enhancing Declarative Temporal Model Mining in Relational Databases: A Preliminary StudySamuel Appleby, Giacomo Bergami, and Graham MorganIn Proceedings of the 27th International Database Engineered Applications Symposium, Heraklion, Crete, Greece, Aug 2023
Propositionalisation tampers the running time of state-of-the-art algorithms in declarative temporal model mining, as they exhaustively generate the clauses instantiated with the results of frequent itemset mining algorithms. Existing algorithms also exploit non-indexed data representations, thus negatively affecting the overall running time. This paper proposes a novel temporal model mining algorithm, Bolt, twinning confidence and support metrics as heuristics for candidate pruning with data structures enabling fast temporal data scanning. Bolt outperforms both state-of-the-art and renditions of existing mining algorithms using KnoBAB as a library.
@inproceedings{ideas2023, author = {Appleby, Samuel and Bergami, Giacomo and Morgan, Graham}, title = {Enhancing Declarative Temporal Model Mining in Relational Databases: A Preliminary Study}, year = {2023}, isbn = {9798400707445}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3589462.3589491}, doi = {10.1145/3589462.3589491}, booktitle = {Proceedings of the 27th International Database Engineered Applications Symposium}, pages = {34–42}, numpages = {9}, keywords = {Temporal Models, Temporal Logic, Knowledge Bases, Data Mining}, location = {Heraklion, Crete, Greece}, series = {IDEAS '23}, dimensions = {true}, } - GRADES-NDA Fast Synthetic Data-Aware Log Generation for Temporal Declarative ModelsGiacomo BergamiIn Proceedings of the 6th Joint Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA), Seattle, WA, USA, Aug 2023
Business Process Management algorithms are heavily limited by suboptimal algorithmic implementations that cannot leverage state-of-the-art algorithms in the field of relational and graph databases. The recent interest in this discipline for various IT sectors (cyber-security, Industry 4.0, and e-Health) calls for defining new algorithms improving the performance of existing ones. This paper focuses on generating several traces collected in a log from declarative temporal models by pre-emptively representing those as a specific type of finite state automaton: we show that this task boils down to a single-source multi-target graph traversal on such automaton where both the number of distinct paths to be visited as well as their length are bounded. This paper presents a novel algorithm running in polynomial time over the size of the declarative model represented as a graph and the desired log’s size. The final experiments show that the resulting algorithm outperforms the state-of-the-art data-aware and dataless sequence generations in business process management.
@inproceedings{grades23, author = {Bergami, Giacomo}, title = {Fast Synthetic Data-Aware Log Generation for Temporal Declarative Models}, year = {2023}, isbn = {9798400702013}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3594778.3594881}, doi = {10.1145/3594778.3594881}, booktitle = {Proceedings of the 6th Joint Workshop on Graph Data Management Experiences \& Systems (GRADES) and Network Data Analytics (NDA)}, articleno = {7}, numpages = {9}, keywords = {graph automata, DFA, synthetic data generator, business process management}, location = {Seattle, WA, USA}, series = {GRADES-NDA '23}, dimensions = {true}, tex = {https://github.com/gyankos/gradesnda23}, } - SWiMM DEEPeR: A Simulated Underwater Environment for Tracking Marine Mammals Using Deep Reinforcement Learning and BlueROV2Samuel Appleby, Kirsten Crane, Giacomo Bergami, and 1 more authorIn IEEE Conference on Games, CoG 2023, Boston, MA, USA, August 21-24, 2023, Aug 2023
This paper offers a feasibility study on using simulated environments for training autonomous underwater vehicles (AUVs). With the goal of monitoring marine megafauna, we propose a Unity-hosted simulation of a realistic open ocean environment, with a focus on simulating Blue Robotics’ BlueROV2. The result is SWiMM DEEPeR 1 , coupling the former simulation with a reinforcement learning (RL) pipeline. Animated marine mammal models emulate the target objects of the real-world deployment scenario, offering a solution in a new application space (conservation) as well as a new problem space (visual active tracking). We provide experiments with respect to each stage of the proposed pipeline: i) image similarity experiments provide evidence for decisions around image rendering and data transfer, ii) autoencoder training demonstrates the feasibility of mapping raw images to low-dimensional feature representations, iii) agent training demonstrates successful self-learnt vehicle control.
@inproceedings{delfino, author = {Appleby, Samuel and Crane, Kirsten and Bergami, Giacomo and McGough, A. Stephen}, title = {SWiMM DEEPeR: {A} Simulated Underwater Environment for Tracking Marine Mammals Using Deep Reinforcement Learning and BlueROV2}, booktitle = {{IEEE} Conference on Games, CoG 2023, Boston, MA, USA, August 21-24, 2023}, pages = {1--8}, publisher = {{IEEE}}, year = {2023}, url = {https://doi.org/10.1109/CoG57401.2023.10333168}, doi = {10.1109/COG57401.2023.10333168}, timestamp = {Tue, 07 May 2024 20:12:08 +0200}, biburl = {https://dblp.org/rec/conf/cig/ApplebyCBM23.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, dimensions = {true}, } - Platform for Energy Efficiency Monitoring Electrical Vehicle in Real World Traffic SimulationReham Almutairi, Giacomo Bergami, Graham Morgan, and 1 more authorIn 2023 IEEE 25th Conference on Business Informatics (CBI), Jun 2023
The increasing popularity and attention in VANETs has prompted researchers to develop accurate and realistic simulation tools. The realistic simulation for VANETs is a challenging task as road networks have high mobility of vehicles. Many efforts have been made in the VANET simulation area to meet the need for coupling network and road traffic simulation. However, none of them permits simulation based on IoT infrastructure. In this work, we are bridging the IoT simulation with the traffic simulation by proposing a novel simulator, Simulator-Bridger. To achieve this, our proposed simulator bridges IoTSim-OsmosisRES with Sumo, a traffic simulator, where the former had to be extended to support mobility vehicles. We substantiate the suitability of our proposed approach by showing how state-of-the-art IoT simulators can manage communication-network traffic information as generated by a real-life urban mobility scenario through VANET simulators.
@inproceedings{simbridger1, author = {Almutairi, Reham and Bergami, Giacomo and Morgan, Graham and Gillgallon, Rohin}, booktitle = {2023 IEEE 25th Conference on Business Informatics (CBI)}, title = {Platform for Energy Efficiency Monitoring Electrical Vehicle in Real World Traffic Simulation}, year = {2023}, volume = {}, number = {}, pages = {1-8}, keywords = {Couplings;Roads;Vehicular ad hoc networks;Traffic control;Road traffic;Energy efficiency;Task analysis;Traffic Simultors;VANET;IoT}, doi = {10.1109/CBI58679.2023.10187450}, issn = {2378-1971}, month = jun, dimensions = {true}, }
2022
- IDEAS Running Temporal Logical Queries on the Relational ModelSamuel Appleby, Giacomo Bergami, and Graham MorganIn Proceedings of the 26th International Database Engineered Applications Symposium, Budapest, Hungary, Jun 2022
State of the art for model checking exploit computationally intensive solutions, bottlenecked by either repeated data access or suboptimal algorithmic implementations. Our solution outperforms the previous solutions while proposing novel temporal logic operators for accessing relational tables.
@inproceedings{ideas22, author = {Appleby, Samuel and Bergami, Giacomo and Morgan, Graham}, title = {Running Temporal Logical Queries on the Relational Model}, year = {2022}, isbn = {9781450397094}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3548785.3548786}, doi = {10.1145/3548785.3548786}, booktitle = {Proceedings of the 26th International Database Engineered Applications Symposium}, pages = {134–143}, numpages = {10}, keywords = {Temporal Logic, Query Plan, Logical Artificial Intelligence, Knowledge Bases}, location = {Budapest, Hungary}, series = {IDEAS '22}, dimensions = {true}, tex = {https://github.com/SamuelAppleby/IDEAS_2022}, } - Cloud Auto-scaling Auditing Approach using BlockchainAhmad A Alsharidah, Masoud Barati, Giacomo Bergami, and 1 more authorIn 2022 IEEE/ACM 15th International Conference on Utility and Cloud Computing (UCC), Jun 2022
Auto-scaling mechanisms are frequently activated when deploying applications in the cloud environment. They are vital to ensure the application is capable of maintaining the requisite Quality of Service. The auto-scaling tools used depend heavily on the performance indicators provided via monitoring tools. Currently, the majority of the monitoring solutions available are constructed by cloud service providers. Potential therefore exists for cloud providers’ non-compliance with the defined autoscaling configurations and dishonest behaviour. Current practice therefore requires a level of trust that the cloud provider will behave in a trustworthy manner. This paper proposes an autoscaling verification mechanism based on blockchain technology to verify resource scaling decisions made by an obligated service provider. We employed a permissioned blockchain network, Hyperledger Fabric, to evaluate the performance of the proposed system as regards transaction throughput, transaction average latency, transaction success and/or failure and transaction send rate.
@inproceedings{boh1, author = {Alsharidah, Ahmad A and Barati, Masoud and Bergami, Giacomo and Ranjan, Rajiv}, booktitle = {2022 IEEE/ACM 15th International Conference on Utility and Cloud Computing (UCC)}, title = {Cloud Auto-scaling Auditing Approach using Blockchain}, year = {2022}, volume = {}, number = {}, pages = {391-398}, keywords = {Cloud computing;Distributed ledger;Quality of service;Benchmark testing;Throughput;Fabrics;Blockchains;Cloud computing;Blockchain;Resource management;Auto-scaling;Cloud monitoring;Compliance Verification;Hyperledger Fabric.}, doi = {10.1109/UCC56403.2022.00068}, dimensions = {true}, }
2021
- IDEASOn Efficiently Equi-Joining GraphsGiacomo BergamiIn Proceedings of the 25th International Database Engineering & Applications Symposium, Montreal, QC, Canada, Jun 2021
Despite the growing popularity of techniques related to graph summarization, a general operator for joining graphs on both the vertices and the edges is still missing. Current languages such as Cypher and SPARQL express binary joins through the non-scalable and inefficient composition of multiple traversal and graph creation operations. In this paper, we propose an efficient equi-join algorithm that is able to perform vertex and path joins over a secondary memory indexed graph, also the resulting graph is serialised in secondary memory. The results show that the implementation of the proposed model outperforms solutions based on graphs, such as Neo4J and Virtuoso, and the relational model, such as PostgreSQL. Moreover, we propose two ways how edges can be combined, namely the conjunctive and disjunctive semantics, Preliminary experiments on the graph conjunctive join are also carried out with incremental updates, thus suggesting that our solution outperforms materialized views over PostgreSQL.
@inproceedings{ideas2021, author = {Bergami, Giacomo}, title = {On Efficiently Equi-Joining Graphs}, year = {2021}, isbn = {9781450389914}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3472163.3472269}, doi = {10.1145/3472163.3472269}, booktitle = {Proceedings of the 25th International Database Engineering \& Applications Symposium}, pages = {222–231}, numpages = {10}, keywords = {Graph Joins, Near-Data Processing, Property Graphs, RDF Graphs}, location = {Montreal, QC, Canada}, series = {IDEAS '21}, dimensions = {true}, } - Aligning Data-Aware Declarative Process Models and Event LogsGiacomo Bergami, Fabrizio Maria Maggi, Andrea Marrella, and 1 more authorIn Business Process Management, Jun 2021
Alignments are a conformance checking strategy quantifying the amount of deviations of a trace with respect to a process model, as well as providing optimal repairs for making the trace conformant to the process model. Data-aware alignment strategies are also gaining momentum, as they provide richer descriptions for deviance detection. Nonetheless, no technique is currently able to provide trace repair solutions in the context of data-aware declarative process models: current approaches either focus on procedural models, or numerically quantify the deviance with no proposed repair strategy. After discussing our working hypotheses, we demonstrate how such a problem can be reduced to a data-agnostic trace alignment problem, while ensuring the correctness of its solution. Finally, we show how to find such a solution leveraging Automated Planning techniques in Artificial Intelligence. Specifically, we discuss how to align traces with data-aware declarative models by adding/deleting events in the trace or by changing the attribute values attached to them.
@inproceedings{bpm21, author = {Bergami, Giacomo and Maggi, Fabrizio Maria and Marrella, Andrea and Montali, Marco}, editor = {Polyvyanyy, Artem and Wynn, Moe Thandar and Van Looy, Amy and Reichert, Manfred}, title = {Aligning Data-Aware Declarative Process Models and Event Logs}, booktitle = {Business Process Management}, year = {2021}, publisher = {Springer International Publishing}, address = {Cham}, pages = {235--251}, isbn = {978-3-030-85469-0}, dimensions = {true}, } - Discovering Declarative Process Model Behavior from Event Logs via Model LearningSimone Agostinelli, Giacomo Bergami, Alessio Fiorenza, and 3 more authorsIn 2021 3rd International Conference on Process Mining (ICPM), Oct 2021
Declarative business process (BP) models define the behavior of BPs as a set of temporal constraints, which can be summarized as a deterministic finite state automaton (DFA). Declarative BP discovery aims at inferring such constraints from event logs. To this aim, it requires as additional input the set of candidate constraints to be verified with respect to the event log. Intuitively, this restricts the discovery task to a conformance checking activity between a predefined set of constraint templates and an event log, preventing to learn any observed behavior that is not captured by those templates. In this paper, we investigate how to leverage Model Learning (ML) for the automated discovery of the DFA underlying the behavior of a declarative BP model, without using any further a-priori information in addition to the event log. To assess the quality of the discovered DFA, we introduce a novel definition of the standard process mining quality metrics, i.e., precision, generalization and simplicity, tailored to DFAs. Finally, a preliminary evaluation performed with real-life logs shows that ML enables to generate extremely simpler DFAs than state-of-the-art BP declarative discovery techniques, keeping similar values of precision and generalization.
@inproceedings{icpm21a, author = {Agostinelli, Simone and Bergami, Giacomo and Fiorenza, Alessio and Maggi, Fabrizio M. and Marrella, Andrea and Patrizi, Fabio}, booktitle = {2021 3rd International Conference on Process Mining (ICPM)}, title = {Discovering Declarative Process Model Behavior from Event Logs via Model Learning}, year = {2021}, volume = {}, number = {}, pages = {48-55}, keywords = {Measurement;Automata;Task analysis;Standards;Business;Model Learning;Declarative Process Models;Finite State Automata;Process Mining Quality Metrics}, doi = {10.1109/ICPM53251.2021.9576870}, issn = {}, month = oct, dimensions = {true}, } - Probabilistic Trace AlignmentGiacomo Bergami, Fabrizio Maria Maggi, Marco Montali, and 1 more authorIn 2021 3rd International Conference on Process Mining (ICPM), Oct 2021
Alignments provide sophisticated diagnostics that pinpoint deviations in a trace with respect to a process model. Alignment-based approaches for conformance checking have so far used crisp process models as a reference. Recent probabilistic conformance checking approaches check the degree of conformance of an event log as a whole with respect to a stochastic process model, without providing alignments. For the first time, we introduce a conformance checking approach based on trace alignments using stochastic Workflow nets. This requires to handle the two possibly contrasting forces of the cost of the alignment on the one hand and the likelihood of the model trace with respect to which the alignment is computed on the other.
@inproceedings{icpm21b, author = {Bergami, Giacomo and Maggi, Fabrizio Maria and Montali, Marco and Peñaloza, Rafael}, booktitle = {2021 3rd International Conference on Process Mining (ICPM)}, title = {Probabilistic Trace Alignment}, year = {2021}, volume = {}, number = {}, pages = {9-16}, keywords = {Costs;Computational modeling;Petri nets;Stochastic processes;Probabilistic logic;Stochastic Petri nets;Conformance Checking;Alignments.}, doi = {10.1109/ICPM53251.2021.9576856}, issn = {}, month = oct, dimensions = {true}, } - A Tool for Computing Probabilistic Trace AlignmentsGiacomo Bergami, Fabrizio Maria Maggi, Marco Montali, and 1 more authorIn Intelligent Information Systems, Oct 2021
Alignments pinpoint trace deviations in a process model and quantify their severity. However, approaches based on trace alignments use crisp process models and recent probabilistic conformance checking approaches check the degree of conformance of an event log with respect to a stochastic process model instead of finding trace alignments. In this paper, for the first time, we provide a conformance checking approach based on trace alignments using stochastic Workflow nets. Conceptually, this requires to handle the two possibly contrasting forces of the cost of the alignment on the one hand and the likelihood of the model trace with respect to which the alignment is computed on the other.
@inproceedings{tool21, author = {Bergami, Giacomo and Maggi, Fabrizio Maria and Montali, Marco and Pe{\~{n}}aloza, Rafael}, editor = {Nurcan, Selmin and Korthaus, Axel}, title = {A Tool for Computing Probabilistic Trace Alignments}, booktitle = {Intelligent Information Systems}, year = {2021}, publisher = {Springer International Publishing}, address = {Cham}, pages = {118--126}, isbn = {978-3-030-79108-7}, dimensions = {true}, tex = {https://github.com/jackbergus/ProbTraceAlignment/releases/tag/1.0}, } - Exploring Business Process Deviance with Sequential and Declarative PatternsGiacomo Bergami, Chiara Di Francescomarino, Chiara Ghidini, and 2 more authorsOct 2021
Business process deviance refers to the phenomenon whereby a subset of the executions of a business process deviate, in a negative or positive way, with respect to their expected or desirable outcomes. Deviant executions of a business process include those that violate compliance rules, or executions that undershoot or exceed performance targets. Deviance mining is concerned with uncovering the reasons for deviant executions by analyzing event logs stored by the systems supporting the execution of a business process. In this paper, the problem of explaining deviations in business processes is first investigated by using features based on sequential and declarative patterns, and a combination of them. Then, the explanations are further improved by leveraging the data attributes of events and traces in event logs through features based on pure data attribute values and data-aware declarative rules. The explanations characterizing the deviances are then extracted by direct and indirect methods for rule induction. Using real-life logs from multiple domains, a range of feature types and different forms of decision rules are evaluated in terms of their ability to accurately discriminate between non-deviant and deviant executions of a process as well as in terms of understandability of the final outcome returned to the users.
@misc{bergami2021exploringbusinessprocessdeviance, title = {Exploring Business Process Deviance with Sequential and Declarative Patterns}, author = {Bergami, Giacomo and Francescomarino, Chiara Di and Ghidini, Chiara and Maggi, Fabrizio Maria and Puura, Joonas}, year = {2021}, eprint = {2111.12454}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, url = {https://arxiv.org/abs/2111.12454}, dimensions = {true}, } - On Declare MAX-SAT and a finite Herbrand Base for data-aware logsGiacomo BergamiOct 2021
This technical report provides some lightweight introduction motivating the definition of an alignment of log traces against Data-Aware Declare Models potentially containing correlation conditions. This technical report is only providing the intuition of the logical framework as a feasibility study for a future formalization and experiment section.
@misc{bergami2021declaremaxsatfiniteherbrand, title = {On Declare MAX-SAT and a finite Herbrand Base for data-aware logs}, author = {Bergami, Giacomo}, year = {2021}, eprint = {2106.07781}, archiveprefix = {arXiv}, primaryclass = {cs.DB}, url = {https://arxiv.org/abs/2106.07781}, dimensions = {true}, } - A Logical Model for joining Property GraphsGiacomo BergamiOct 2021
The present paper upgrades the logical model required to exploit materialized views over property graphs as intended in the seminal paper "A Join Operator for Property Graphs". Furthermore, we provide some computational complexity proofs strengthening the contribution of a forthcoming graph equi-join algorithm proposed in a recently accepted paper.
@misc{bergami2021logicalmodeljoiningproperty, title = {A Logical Model for joining Property Graphs}, author = {Bergami, Giacomo}, year = {2021}, eprint = {2106.14766}, archiveprefix = {arXiv}, primaryclass = {cs.LO}, url = {https://arxiv.org/abs/2106.14766}, dimensions = {true}, }
2020
- IDEASHierarchical embedding for DAG reachability queriesGiacomo Bergami, Flavio Bertini, and Danilo MontesiIn Proceedings of the 24th Symposium on International Database Engineering & Applications, Seoul, Republic of Korea, Oct 2020
Current hierarchical embeddings are inaccurate in both reconstructing the original taxonomy and answering reachability queries over Direct Acyclic Graph. In this paper, we propose a new hierarchical embedding, the Euclidean Embedding (EE), that is correct by design due to its mathematical formulation and associated lemmas. Such embedding can be constructed during the visit of a taxonomy, thus making it faster to generate if compared to other learning-based embeddings. After proposing a novel set of metrics for determining the embedding accuracy with respect to the reachability queries, we compare our proposed embedding with state-of-the-art approaches using full trees from 3 to 1555 nodes and over a real-world Direct Acyclic Graph of 1170 nodes. The benchmark shows that EE outperforms our competitors in both accuracy and efficiency.
@inproceedings{ideas20, author = {Bergami, Giacomo and Bertini, Flavio and Montesi, Danilo}, title = {Hierarchical embedding for DAG reachability queries}, year = {2020}, isbn = {9781450375030}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3410566.3410583}, doi = {10.1145/3410566.3410583}, booktitle = {Proceedings of the 24th Symposium on International Database Engineering \& Applications}, articleno = {24}, numpages = {10}, keywords = {tree, taxonomy, reachability query, hierarchical embedding, DAG}, location = {Seoul, Republic of Korea}, series = {IDEAS '20}, dimensions = {true}, }
2019
- A framework supporting imprecise queries and dataGiacomo BergamiOct 2019
This technical report provides some lightweight introduction and some generic use case scenarios motivating the definition of a database supporting uncertainties in both queries and data. This technical report is only providing the logical framework, which implementation is going to be provided in the final paper.
@misc{bergami2019frameworksupportingimprecisequeries, title = {A framework supporting imprecise queries and data}, author = {Bergami, Giacomo}, year = {2019}, eprint = {1912.12531}, archiveprefix = {arXiv}, primaryclass = {cs.DB}, url = {https://arxiv.org/abs/1912.12531}, dimensions = {true}, } - IDEASOn approximate nesting of multiple social network graphs: a preliminary studyGiacomo Bergami, Flavio Bertini, and Danilo MontesiIn Proceedings of the 23rd International Database Applications & Engineering Symposium, Athens, Greece, Oct 2019
A fundamental problem in Social Network Analysis is how to move from single-layer to multi-layer, which provide a holistic view. User profiles resolution has received considerable attention since it allows to match users on different online social networks (OSNs). However, to the best of our knowledge, no study has focused on nesting operation for merging OSNs graphs. This work is a first step in the direction of defining the data model and the algorithm to perform approximate nesting of multiple OSNs graphs, based on user features. We provide initial experimental evidence based on synthetic data.
@inproceedings{ideas19, author = {Bergami, Giacomo and Bertini, Flavio and Montesi, Danilo}, title = {On approximate nesting of multiple social network graphs: a preliminary study}, year = {2019}, isbn = {9781450362498}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3331076.3331081}, doi = {10.1145/3331076.3331081}, booktitle = {Proceedings of the 23rd International Database Applications \& Engineering Symposium}, articleno = {40}, numpages = {5}, keywords = {multilayer social networks, graph nesting, approximate graph query answering}, location = {Athens, Greece}, series = {IDEAS '19}, dimensions = {true}, }
2018
- A new Nested Graph Model for Data IntegrationGiacomo BergamiAlma Mater Studiorum – Università di Bologna, Apr 2018
Despite graph data gained increasing interest in several fields, no data model suitable for both querying and integrating differently structured graph and (semi)structured data has been currently conceived. The lack of operators allowing combinations of (multiple) graphs in current graph query languages (graph joins), and on graph data structure allowing neither data integration nor nested multidimensional representations (graph nesting) are a possible motivation. In order to make such data integration possible, this thesis proposes a novel model (General Semistructured data Model) allowing the representation of both graphs and arbitrarily nested contents (e.g., one node can be contained by more than just one parent node), thus allowing the definition of a nested graph model, where both vertices and edges may include (overlapping) graphs. We provide two graph joins algorithms (Graph Conjunctive Equijoin Algorithm and Graph Conjunctive Less-equal Algorithm) and one graph nesting algorithm (Two HOp Separated Patterns). Their evaluation on top of our secondary memory representation showed the inefficiency of existing query languages’ query plan on top of their respective data models (relational, graph and document-oriented). In all three algorithms, the enhancement was possible by using an adjacency list graph representation, thus reducing the cost of joining the vertices with their respective outgoing (or ingoing) edges, and by associating hash values to both vertices and edges. As a secondary outcome of this thesis, a general data integration scenario is provided where both graph data and other semistructured and structured data could be represented and integrated into the General Semistructured data Model. A new query language outlines the feasibility of this approach (General Semistructured Query Language) over the former data model, also allowing to express both graph joins and graph nestings. This language is also capable of representing both traversal and data manipulation operators.
@phdthesis{amsdottorato8348, author = {Bergami, Giacomo}, year = {2018}, month = apr, title = {A new Nested Graph Model for Data Integration}, school = {Alma Mater Studiorum -- Università di Bologna}, url = {http://amsdottorato.unibo.it/8348/}, keywords = {Graph Join, Graph Nesting, Nested Graph, Property Graph, General Semistructured Data Model, GSQL}, dimensions = {true}, tex = {https://github.com/gyankos/PhDThesis-Latex} } - Predicting Frailty Condition in Elderly Using Multidimensional Socioclinical DatabasesFlavio Bertini, Giacomo Bergami, Danilo Montesi, and 3 more authorsProceedings of the IEEE, Apr 2018
Smart cities face the challenge of combining sustainable national welfare with high living standards. In the last decades, life expectancy increased globally, leading to various age-related issues in almost all developed countries. Frailty affects elderly who are experiencing daily life limitations due to cognitive and functional impairments and represents a remarkable burden for national health systems. In this paper, we proposed two different predictive models for frailty by exploiting 12 socioclinical databases. Emergency hospitalization or all-cause mortality within a year were used as surrogates of frailty. The first model was able to assign a frailty risk score to each subject older than 65 years old, identifying five different classes for tailor made interventions. The second prediction model assigned a worsening risk score to each subject in the first nonfrail class, namely the probability to move in a higher frailty class within the year. We conducted a retrospective cohort study based on the whole elderly population of the Municipality of Bologna, Italy. We created a baseline cohort of 95 368 subjects for the frailty risk model and a baseline cohort of 58 789 subjects for the worsening risk model, respectively. To evaluate the predictive ability of our models through calibration and discrimination estimates, we used, respectively, a six-year and a four-year observation period. Good discriminatory power and calibration were obtained, demonstrating a good predictive ability of the models.
@article{oplon2, author = {Bertini, Flavio and Bergami, Giacomo and Montesi, Danilo and Veronese, Giacomo and Marchesini, Giulio and Pandolfi, Paolo}, journal = {Proceedings of the IEEE}, title = {Predicting Frailty Condition in Elderly Using Multidimensional Socioclinical Databases}, year = {2018}, volume = {106}, number = {4}, pages = {723-737}, keywords = {Senior citizens;Predictive models;Medical services;Data warehouses;Databases;Statistics;Sustainable development;Aging society;frailty condition;healthcare data analysis;predictive models;smart city;smart healthcare}, doi = {10.1109/JPROC.2018.2791463}, dimensions = {true}, } - GRADES-NDATHoSP: an algorithm for nesting property graphsGiacomo Bergami, André Petermann, and Danilo MontesiIn Proceedings of the 1st ACM SIGMOD Joint International Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA), Houston, Texas, Apr 2018
Despite the growing popularity of techniques related to graph summarization, a general operator for the flexible nesting of graphs is still missing. We propose a novel nested graph data model and a powerful graph nesting operator. In contrast to existing approaches, our approach is able to summarize vertices and paths among vertex groups within a single query. Further on, our model supports partial nestings under the preservation of original graph elements as well as the full recovery of the original graph. We propose an efficient nesting algorithm (THoSP) that is able to perform vertex and path nestings in a single visit of the input graph. Results of an experimental evaluation show that THoSP outperforms equivalent implementations based on graph (Cypher, SPARQL), relational (SQL) and document oriented (ArangoDB) databases.
@inproceedings{gradesnda18, author = {Bergami, Giacomo and Petermann, Andr\'{e} and Montesi, Danilo}, title = {THoSP: an algorithm for nesting property graphs}, year = {2018}, isbn = {9781450356954}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3210259.3210267}, doi = {10.1145/3210259.3210267}, booktitle = {Proceedings of the 1st ACM SIGMOD Joint International Workshop on Graph Data Management Experiences \& Systems (GRADES) and Network Data Analytics (NDA)}, articleno = {8}, numpages = {10}, keywords = {nested property graphs, nested graphs, graph nesting}, location = {Houston, Texas}, series = {GRADES-NDA '18}, dimensions = {true}, tex = {https://github.com/gyankos/GraphNesting}, } - GAIA - A Multi-media Multi-lingual Knowledge Extraction and Hypothesis Generation SystemTongtao Zhang, Ananya Subburathinam, Ge Shi, and 31 more authorsIn Proceedings of the 2018 Text Analysis Conference, TAC 2018, Gaithersburg, Maryland, USA, November 13-14, 2018, Apr 2018
@inproceedings{tac18, author = {Zhang, Tongtao and Subburathinam, Ananya and Shi, Ge and Huang, Lifu and Lu, Di and Pan, Xiaoman and Li, Manling and Zhang, Boliang and Wang, Qingyun and Whitehead, Spencer and Ji, Heng and Zareian, Alireza and Akbari, Hassan and Chen, Brian and Zhong, Ruiqi and Shao, Steven and Allaway, Emily and Chang, Shih{-}Fu and McKeown, Kathleen R. and Li, Dongyu and Huang, Xin and Sun, Kexuan and Peng, Xujun and Gabbard, Ryan and Freedman, Marjorie and Kejriwal, Mayank and Nevatia, Ram and Szekely, Pedro A. and Kumar, T. K. Satish and Sadeghian, Ali and Bergami, Giacomo and Dutta, Sourav and Rodr{\'{\i}}guez, Miguel E. and Wang, Daisy Zhe}, title = {{GAIA} - {A} Multi-media Multi-lingual Knowledge Extraction and Hypothesis Generation System}, booktitle = {Proceedings of the 2018 Text Analysis Conference, {TAC} 2018, Gaithersburg, Maryland, USA, November 13-14, 2018}, publisher = {{NIST}}, year = {2018}, url = {https://tac.nist.gov/publications/2018/participant.papers/TAC2018.GAIA.proceedings.pdf}, timestamp = {Wed, 26 Jul 2023 07:56:46 +0200}, biburl = {https://dblp.org/rec/conf/tac/ZhangSSHLPLZWWJ18.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, dimensions = {true}, }
2017
- A Join Operator for Property GraphsGiacomo Bergami, Matteo Magnani, and Danilo MontesiIn Proceedings of the Workshops of the EDBT/ICDT 2017 Joint Conference (EDBT/ICDT 2017), Venice, Italy, March 21-24, 2017, Apr 2017
In the graph database literature the term “join” does not re- fer to an operator combining two graphs, but involves path traversal queries over a single graph. Current languages ex- press binary joins through the combination of path traversal queries with graph creation operations. Such solution proves to be not efficient. In this paper we introduce a binary graph join opera- tor and a corresponding algorithm outperforming the solu- tion proposed by query languages for either graphs (Cypher, SPARQL) and relational databases (SQL). This is achieved by using a specific graph data structure in secondary mem- ory showing better performance than state of the art graph libraries (Boost Graph Library, SNAP) and database sys- tems (Sparksee).
@inproceedings{graphq17, author = {Bergami, Giacomo and Magnani, Matteo and Montesi, Danilo}, editor = {Ioannidis, Yannis E. and Stoyanovich, Julia and Orsi, Giorgio}, title = {A Join Operator for Property Graphs}, booktitle = {Proceedings of the Workshops of the {EDBT/ICDT} 2017 Joint Conference {(EDBT/ICDT} 2017), Venice, Italy, March 21-24, 2017}, series = {{CEUR} Workshop Proceedings}, volume = {1810}, publisher = {CEUR-WS.org}, year = {2017}, url = {https://ceur-ws.org/Vol-1810/GraphQ\_paper\_04.pdf}, timestamp = {Fri, 10 Mar 2023 16:23:45 +0100}, biburl = {https://dblp.org/rec/conf/edbt/BergamiMM17.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, dimensions = {true}, } - Mining and ranking of generalized multi-dimensional frequent subgraphsAndré Petermann, Giovanni Micale, Giacomo Bergami, and 2 more authorsIn 2017 Twelfth International Conference on Digital Information Management (ICDIM), Apr 2017
Frequent pattern mining is an important research field and can be applied to different labeled data structures ranging from itemsets to graphs. There are scenarios where a label can be assigned to a taxonomy and generalized patterns can be mined by replacing labels by their ancestors. In this work, we propose a novel approach to generalized frequent subgraph mining. In contrast to existing work, our approach considers new requirements from use cases beyond molecular databases. In particular, we support directed multigraphs as well as multiple taxonomies to deal with the different semantic meaning of vertices. Since results of generalized frequent subgraph mining can be very large, we use a fast analytical method of p-value estimation to rank results by significance. We propose two extensions of the popular gSpan algorithm that mine frequent subgraphs across all taxonomy levels. We compare both algorithms in an experimental evaluation based on a database of business process executions represented by graphs.
@inproceedings{icdim17, author = {Petermann, André and Micale, Giovanni and Bergami, Giacomo and Pulvirenti, Alfredo and Rahm, Erhard}, booktitle = {2017 Twelfth International Conference on Digital Information Management (ICDIM)}, title = {Mining and ranking of generalized multi-dimensional frequent subgraphs}, year = {2017}, volume = {}, number = {}, pages = {236-245}, keywords = {Taxonomy;Data mining;Data models;Mathematical model;Data structures;Itemsets}, doi = {10.1109/ICDIM.2017.8244685}, dimensions = {true}, }
2016
- Predicting frailty in elderly people using socio-clinical databasesFlavio Bertini, Giacomo Bergami, Danilo Montesi, and 1 more authorIn 5th Workshop on Data Mining for Medicine and Healthcare, Jun 2016
Life expectancy increases globally and brings out several challenges in almost all developed countries all around the world. Early screening allows to carry out policies to prevent adverse age-related events and to better distribute the associated financial burden on social and healthcare systems. One of the main issues correlated to a longer lifespan is the onset of the frailty condition that typically characterizes who is starting to experience daily life limitations due to cognitive and functional impairment. In literature there are many different definitions of frailty condition, mainly due to the large number of variables that can reduce the autonomy of the elderly. We extend the definition proposed by the Department of Health of the UK National Health Service, with which a frail subject is at risk of hospitalisation or death within a year. In particular, in this paper we propose a predictive model for frailty condition based on 26 variables from 11 socio-clinical databases. The model assigns a frailty risk index in the range 0 to 100 to each subject aged over 65 years old. The risk index is stratified in 5 expected risk classes and allows to carry out different tailored interventions. To evaluate our method, we use a four-year depth dataset of about 100 000 over 65 subjects. The obtained results are compared to a dataset of patients being treated in local health services.
@inproceedings{oplon1, title = {Predicting frailty in elderly people using socio-clinical databases}, author = {Bertini, Flavio and Bergami, Giacomo and Montesi, Danilo and Pandolfi, Paolo}, year = {2016}, url = {https://archive.siam.org/meetings/sdm16/SDMDMMH.pdf}, month = jun, booktitle = {5th Workshop on Data Mining for Medicine and Healthcare}, address = {New York, NY}, series = {Example Conference Proceedings}, pages = {65--73}, organization = {SIAM}, publisher = {SIAM}, abbrv = {SIAM}, dimensions = {true}, } - On Joining GraphsGiacomo Bergami, Matteo Magnani, and Danilo MontesiJun 2016
3In the graph database literature the term "join" does not refer to an operator used to merge two graphs. In particular, a counterpart of the relational join is not present in existing graph query languages, and consequently no efficient algorithms have been developed for this operator. This paper provides two main contributions. First, we define a binary graph join operator that acts on the vertices as a standard relational join and combines the edges according to a user-defined semantics. Then we propose the "CoGrouped Graph Conjunctive θ-Join" algorithm running over data indexed in secondary memory. Our implementation outperforms the execution of the same operation in Cypher and SPARQL on major existing graph database management systems by at least one order of magnitude, also including indexing and loading time.
@misc{rej1, title = {On Joining Graphs}, author = {Bergami, Giacomo and Magnani, Matteo and Montesi, Danilo}, year = {2016}, eprint = {1608.05594}, archiveprefix = {arXiv}, primaryclass = {cs.DB}, url = {https://arxiv.org/abs/1608.05594}, dimensions = {true}, }
2014
- Hypergraph Mining for Social NetworksGiacomo BergamiAlma Mater Studiorum – Università di Bologna, Jun 2014
Nowadays, more and more data is collected in large amounts, such that the need of studying it both efficiently and profitably is arising; we want to acheive new and significant informations that weren’t known before the analysis. At this time many graph mining algorithms have been developed, but an algebra that could systematically define how to generalize such operations is missing. In order to propel the development of a such automatic analysis of an algebra, We propose for the first time (to the best of my knowledge) some primitive operators that may be the prelude to the systematical definition of a hypergraph algebra in this regard.
@mastersthesis{amslaurea7106, author = {Bergami, Giacomo}, year = {2014}, school = {Alma Mater Studiorum -- Università di Bologna}, title = {Hypergraph Mining for Social Networks}, keywords = {hypergraph datamining, data mining algebra, relational algebra, relational, tensor, matrix}, url = {http://amslaurea.unibo.it/7106/}, dimensions = {true}, }
2012
- Pjproject su Android: uno scontro su più livelliGiacomo BergamiAlma Mater Studiorum – Università di Bologna, Jun 2012
(Translated from Italian) The steadily increasing use of computerized mobile devices pushes every developer to wonder what their practical applications might be. Consequently, knowing their potential and technical characteristics, the developer wonders if such devices can run the same programs they use daily without the need (and the desire) to reinvent the wheel. This desire, driven by practical necessity, guides such developer to choose development systems allowing them to investigate the problems and deepen their accredited solutions: For this reason, the “development platforms” that are gradually establishing themselves (if not already consolidating) are constituted from GNU / Linux and Android operating system. The second poses attractive prospects, as Android both adopts a customary fork of the Linux kernel while gaining momentum on the business world. Nevertheless, Android’s developers imposed on their system some architectural limitations: these can be leveraged by hackers - see device rooting - which, by knowing the weaknesses of GNU/Linux systems, might easily overcome some security restrictions. These still allow the enthusiast to learn more about the GNU / Linux world by analyzing the architectural differences between the two systems.
@mastersthesis{triennale, author = {Bergami, Giacomo}, year = {2012}, school = {Alma Mater Studiorum -- Università di Bologna}, title = { Pjproject su Android: uno scontro su più livelli }, keywords = {android, porting, pjsip, pjproject, binder}, url = {https://amslaurea.unibo.it/4441/}, dimensions = {true}, tex = {https://github.com/jackbergus/pjproject-over-android}, }